
TTS project update 1 - adding texture to my generated speech
Introducing a pool of voices and choices in rate of speech, pitch and volume gain.

TL; DR
In this post, I’d like to share an update on work to address some of the limitations in my text to speech project for Elite Dangerous.. Namely:
- Single voice is used for the synthesis; and
- Pitch, tone and emphasis are unchanged from defaults.
If you’d like to see the result of the work so far, here is a brief overview video, I’ll describe how we got here below:
Review of the current setup
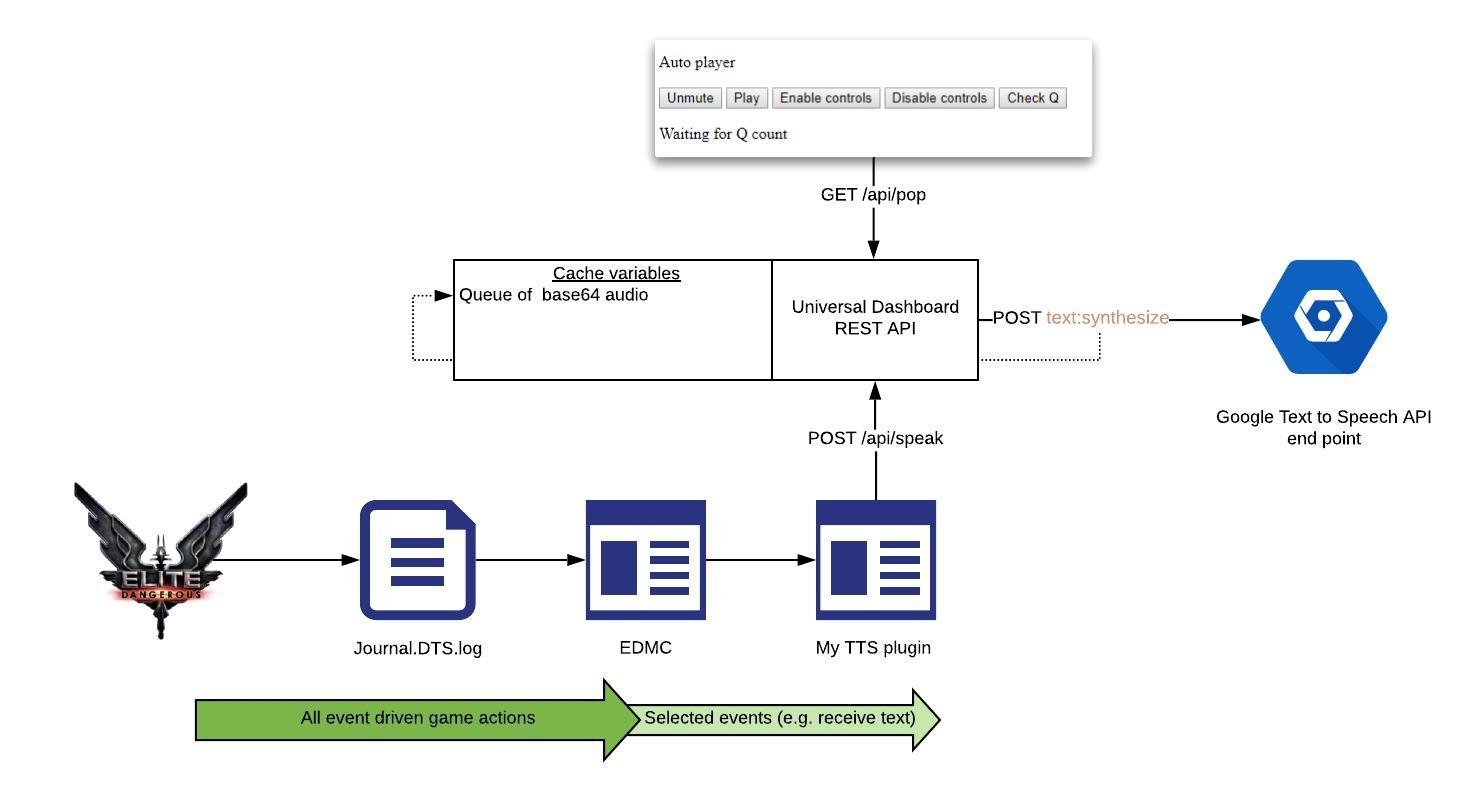
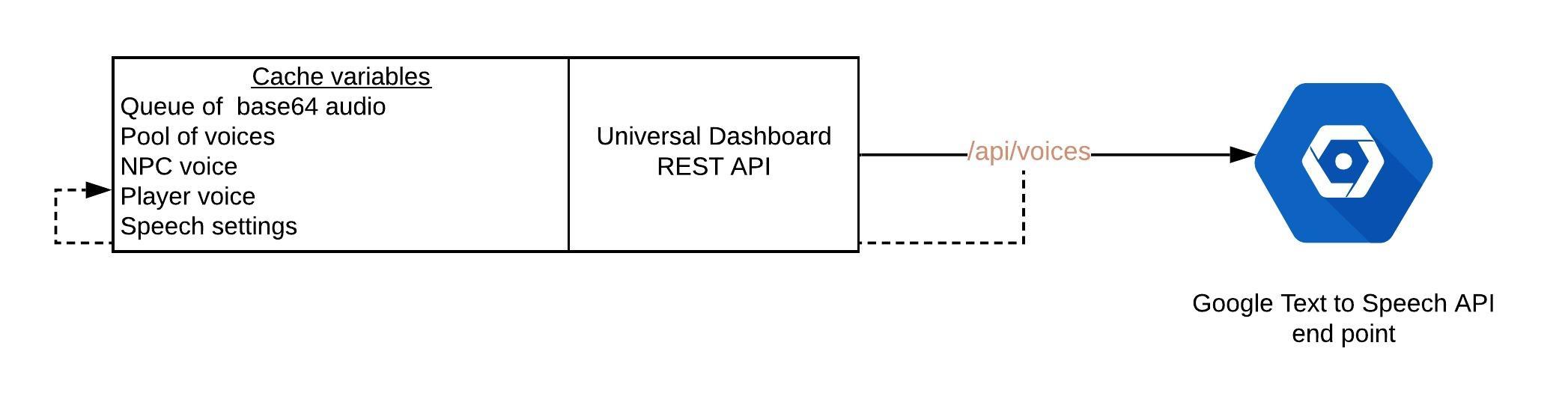
The project consists of:
- An EDMC plugin to capture game events of interest. Events such as
ReceiveTextare forwarded to/api/speak. - A series of PowerShell REST endpoints via Universal Dashboard which triggers assigned code. For example, a call to
/api/speakwill request synthetic voice from Google’stext:synthesizeendpoint and store the result in a queue (to preserve the order of playback). - A web front end which takes the latest audio off the queue via
/api/popand plays it.
Voice selection and speech settings
Universal Dashboard modifications
As part of initialising the Universal Dashboard REST API a call is made to GCP /api/voices to list voices matching en-gb. A default voice is selected from the pool so that NPC and players get a different voice. Additionally, I needed $Cache: variables to hold the voice pool, voice mappings and voice settings.
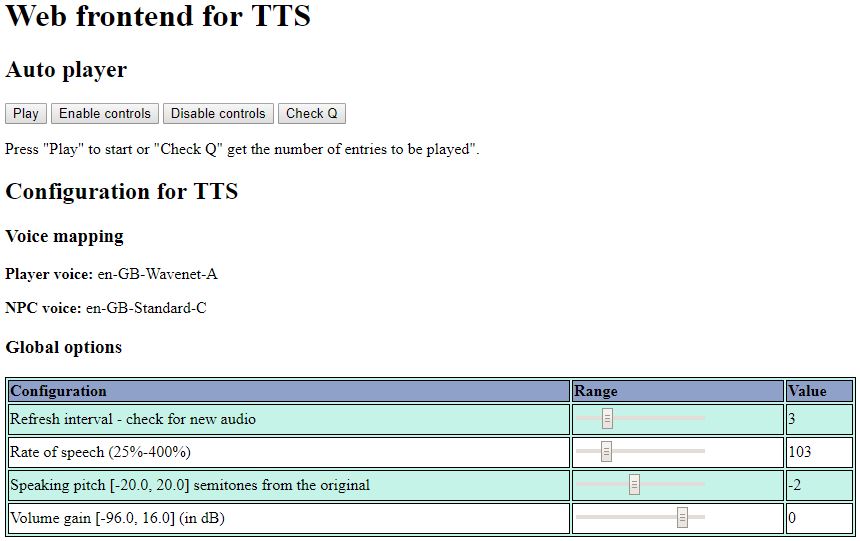
Web front end modifications
Let’s preface this by saying that GUI design is not my strong point. We can generously describe what I produced as functional. In this update we now have:
- Configurable refresh time.
Whenever there is no audio in the queue, the player will wait the prescribed time before checking for new audio. - Sliders for configurable synthetic speech properties such as: rate of speech, speaking pitch and volume gain.
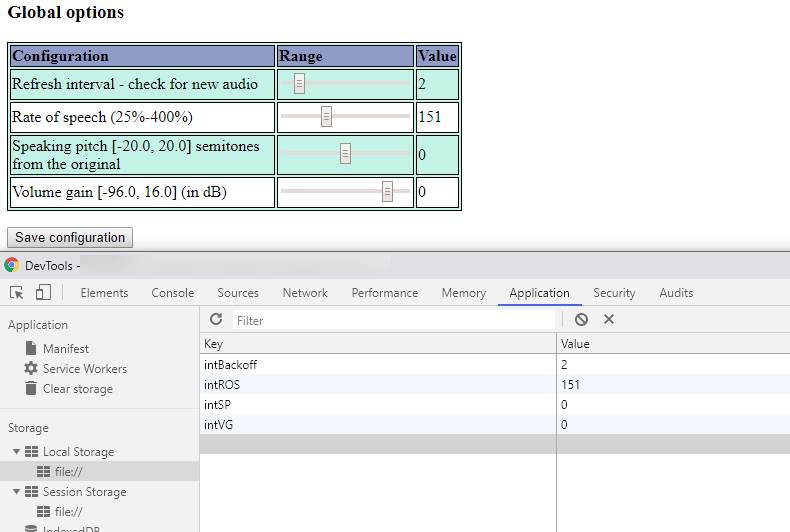
Additionally, these settings persist between sessions, achieved via the Web Storage API.
In conclusion
I have made progress in addressing the two listed limitations. Further work is needed to make better use of the voice pool to expand beyond two voices. Additionally, I’m considering how best to automatically randomise and persist the rate of speech and pitch so that there is some difference in each speech generation.
Share this post