
API Diversions
Experimenting with a new API via Cloudflare workers.
TL; DR
Recently reinvigorated with my new UI work, I set myself to task with simplifying the front end player code. No matter how I looked at it, I’d needed to rewrite the back end API to support a front end rewrite. But what if I didn’t precisely need to do that? Enter stage left, Cloudflare Workers.
Below I explain how I arrived at this. If you would like to view the Worker code, you can do so here. If you would like to view the sites (and compare), you may do so here:
Motivation
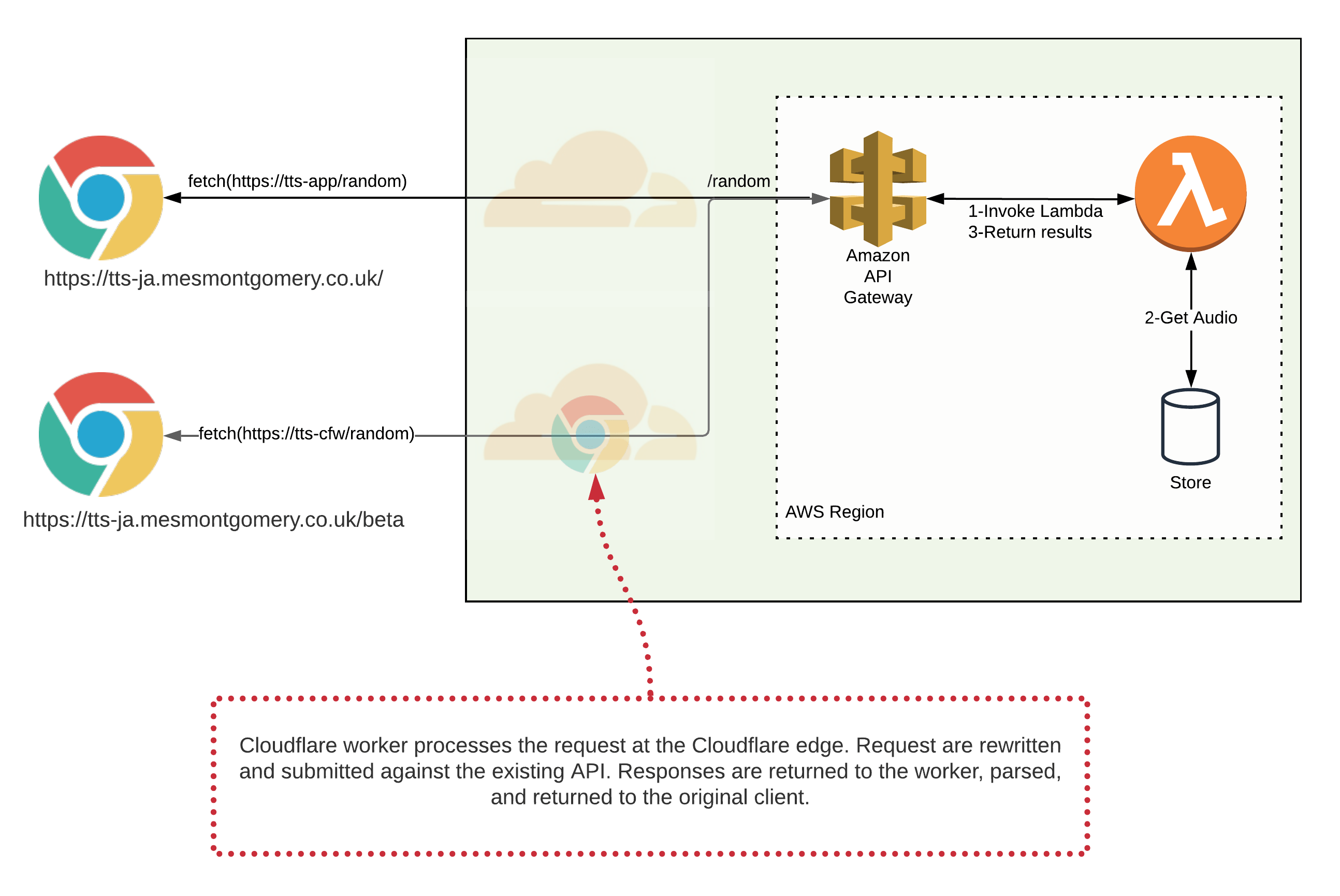
The front end code treats each audio source discretely. In truth, the front end code to support each differs only by the URL called. The URL difference’s significance lies in its relationship with the code providing the API.
- ‘/v1/a-rs’ for Ron Swanson audio.
- ‘/v1/a-sv443’ for sv443’s JokeAPI audio.
- ‘/v1/a-ich’ foricanhazdadjoke.com’s audio.
- ‘/v1/a-qg’ for Quote Garden’s audio.
Each of the above supports a single query string parameter of ’entryid’, the SHA265 hash of an entry in the DB.
- ‘/v1/random’ which returns IDs used with the above routes via the query string parameter.
Each of the above also has a discrete Lambda function. I felt that I could consolidate each to a single URL, allowed the front end to simplify. I want to try this before addressing any back end changes.
Introducing Cloudflare Workers
Cloudflare workers are a serverless technology which allows you to run code to process proxied requests. Cloudflare describes this in much more detail here, and they provide lots of examples.
Cloudflare documents Workers suited to the job of API middleware. I endeavoured to create a Worker that translated calls from my proposed API into the existing.
Cloudflare offers a free tier which more than suits my needs for this. It is available at the time of writing to any Cloudflare plan subject to some limits.
Using Cloudflare Workers to mock up the proposed API
I considered consolidating the API to the following:
- ‘/v1/random’
- ‘/v1/random?contentCode=XY&entryid=ABC’
The proposed API exchanges the content specific API routes for the ‘contentCode’ query string parameter.
For example, a call to /v1/random?contentCode=RS&entryid=ABC for Ron Swanson audio would in effect generate a call to /v1/a-rs?entryid=ABC.
If successful, I could write an updated front end and evaluate the new API structure.
Of CORS, there would be challenges
One of the AWS API gateway benefits is the built-in support for Cross-Origin Resource Sharing (CORS).
In a parallel deployment, such as I had chosen, putting API middleware would surface issues for the client using the alternative FQDN.
I chose to solve it within the Cloudflare worker itself. Based on the requested hostname, the worker would return an appropriate value for ‘access-control-allow-origin’.
//Access control constants
const thisDefaultAllowedOrigin = "http://jamestest.org:1234";
const allowedOrigins = { "tts-cfw-test.mesmontgomery.co.uk": "http://jamestest.org:5500","tts-cfw.mesmontgomery.co.uk":"https://tts-ja.mesmontgomery.co.uk"};
//within the handleRequest function...
//set the allowed origin based on requested hostname
if (url.hostname in allowedOrigins){
thisAllowedOrigin = allowedOrigins[url.hostname];
}
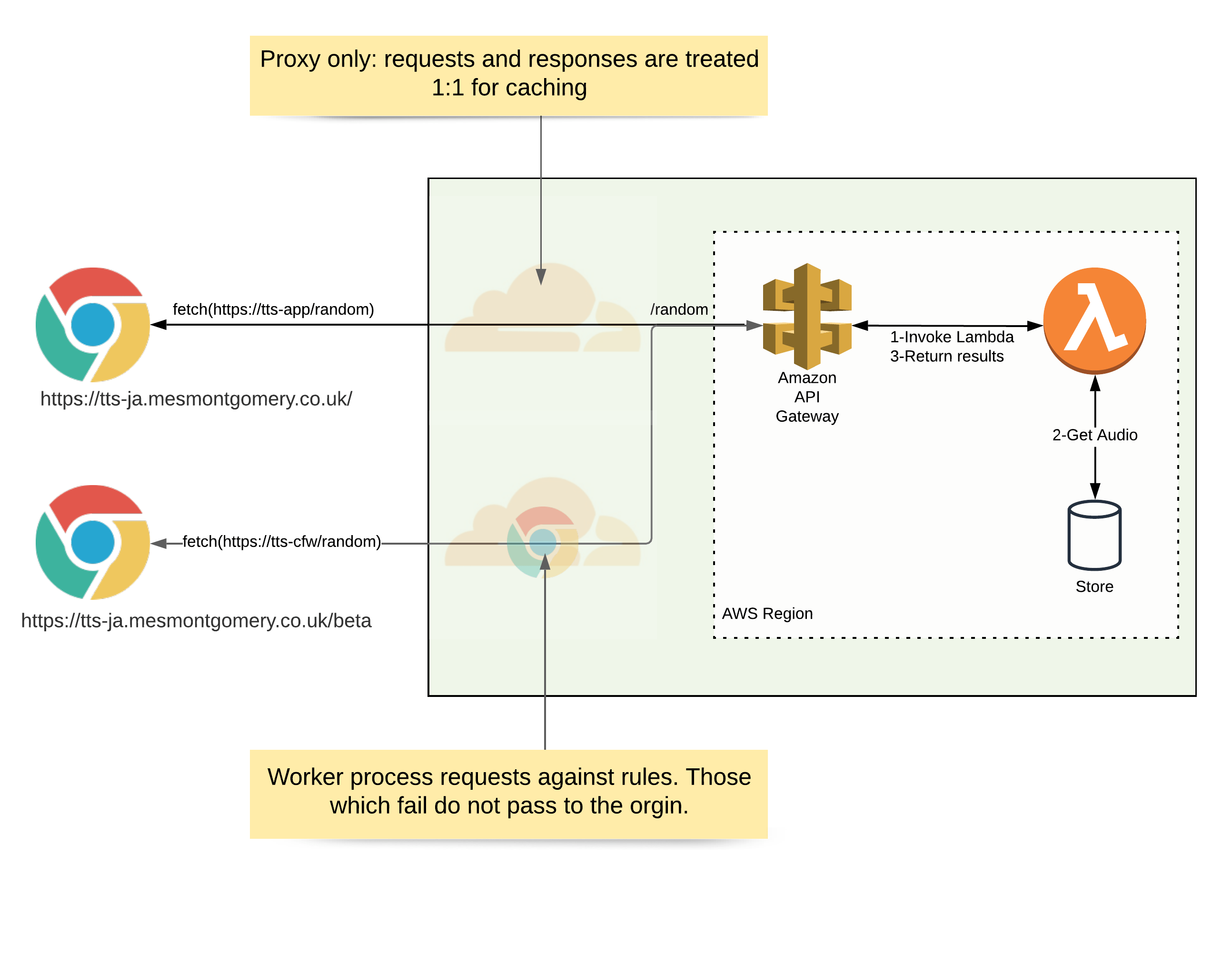
Protecting your origin with in-line validation
It is a common concern that your application API is effectively bare to the internet.
Of course, you can implement all the validation you wish within your client code, but what if requests are sent directly to your API? Inevitably request verification takes place at your origin too, to be safe.
The challenge with request validation at your origin is that it consumes resources.
The position of Cloudflare Workers allows them to perform some request hygiene. It doesn’t release you from API request validation, but it does pre-filter it.
In my case, I configured my worker to validate the format of entryid.
We can test for a valid entryid value by evaluating with regex. The expected value, SHA256 represented in hexadecimal, is exactly 64 characters in length. Each character must be one of a-f/A-F,0-9. We can test with the following:
function isSHA256(h) {
let re = new RegExp('[0-9A-Fa-f]{64}');
return (re.test(h))
}//end of isSha256
Furthermore, the Cloudflare Worker will drop any original request elements irrelevant to my API from the onward request. In summary, it will process requests with the following parameters:
- contentCode
- entryID
The contentCode parameter must be within an expected set of values. At the same time, entryID must be the SHA256 format described above.
Improved caching control
My caching strategy to-date was to use Cloudflare page rules. They achieved the primary goal of absorbing valid repeat requests, serving these from the cache.
However, they did not offer any protection against randomly generated query strings. In this case, Cloudflare would see these as a cache miss and request content from my origin.
I use the Cloudflare worker to cache on the normalised URL, rather than the initially requested address. Padded URLs will map to contentCode and entryID caches entries only. For example:
| Requested URL | Fetched URL |
|---|---|
| https://cfw-fqdn/?contentCode=ICH&entryID=SHA256value | https://backend-fqdn/?contentCode=ICH&entryID=SHA256value |
| https://cfw-fqdn/?contentCode=ICH&entryID=SHA256value&foo=true | https://backend-fqdn/?contentCode=ICH&entryID=SHA256value |
| https://cfw-fqdn/?contentCode=ICH&entryID=SHA256value&foo=true&index=1 | https://backend-fqdn/?contentCode=ICH&entryID=SHA256value |
The fetched URL is our cache key.
if(expectedContentCode){
//use the created URL as the cache key
//check for presence in the cache, return that if found. Otherwise, fetch from the origin.
let thisCacheKey = thisURL;
let response = await cache.match(thisCacheKey);
if (!response) {
const originalRepsonse = await fetch(thisURL);
response = new Response(originalRepsonse.body,originalRepsonse.headers);
response.headers.set("Content-Type", "application/json");
response.headers.set("Cache-Control", "public,max-age=60");
response.headers.set("Access-Control-Allow-Origin", thisAllowedOrigin);
event.waitUntil(cache.put(thisCacheKey,response.clone()));
}
return response;
}
The Cache-Control header determines how long Cloudflare retains the item in the cache. It is set low at 60 seconds for demonstration purposes only. Cloudflare page rules already scope the fetched URL; in reality, the answers cache for longer.
Conclusion
I intended to evaluate if there was merit in consolidating the API routes. The front end code to consume this API features less complexity and duplication on review.
There is value in exploring the work to consolidate the Lambda functions into a single API route.
When I complete that work, I will be more satisfied overall. And I expect to leave an element of Cloudflare workers in place for improved caching control and request hygiene.
Related posts
- New UI for my text-to-speech player
- Introducing async to my serverless text-to-speech player for jokes and quotes
- My serverless “jokes and quotes” player
Acknowledgements
- Thanks to opstree for their most comprehensive writeup on the Cloudflare cache API.
- Thanks to the Cloudflare documentation contributors for their example on how to use the cache API
- Thanks to OpenMoji for the ballon, book and speech parrot. I have modified the colours on the parrot.
- And thanks to the Lorem Ipsum site for their generator.
Share this post