
Order, order!
Using AWS Lambda with the Todoist Sync API

TL; DR
A year ago, I took to AWS to solve a label ordering challenge in my productivity application Todoist. I’ve summarised it in this project page along with the outcome of this addition.
I recently revisited to see if the REST API was updated to allow reordering of items. It had not. The relevant property was read-only, and therefore, the functionality was still exclusive to the Sync API.
I took this as an opportunity to learn the Sync API for which there was an official Python library. Additionally, the need for an external library would allow me to experiment with AWS deployment packages and layers for Lambda.
You can find all my code and supporting files for this on my Github page.
The challenge
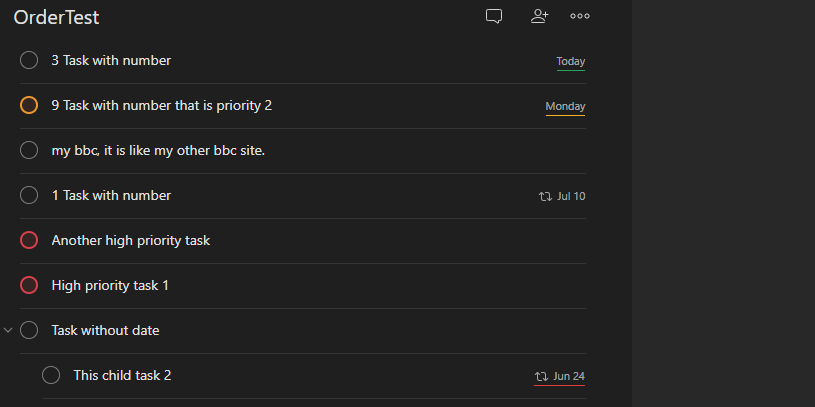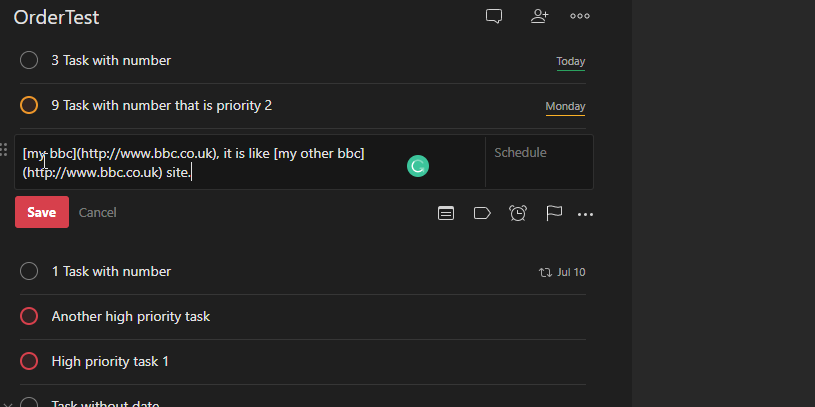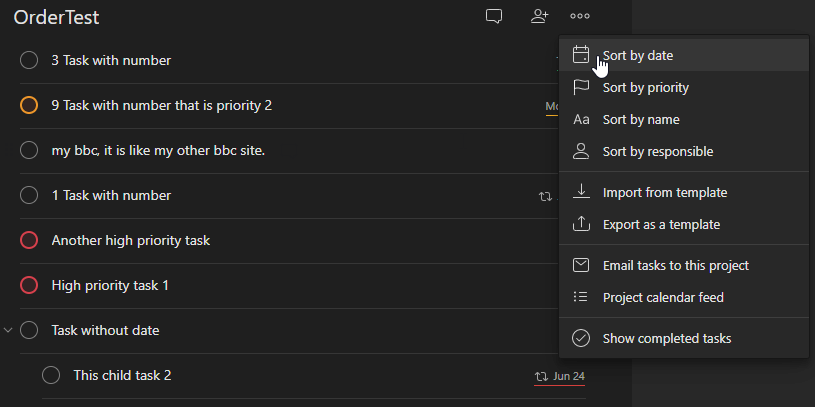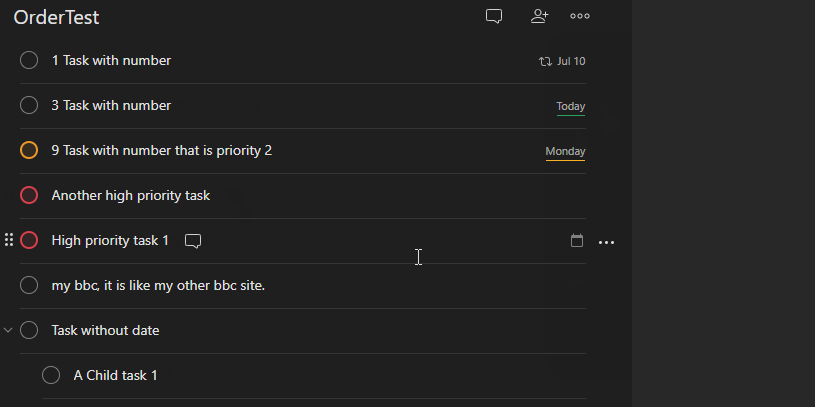
I intended to automate the sorting functionality that is present in the application already via manual action. These are:
- Sort by date
- Sort by priority
- Sort by name
Furthermore, rather than enforce a global sort, each project should have a default sort or be left to the current manual sorting.
The solution
Retrieve project items
The first step is to sync state with Todoist and retrieve our project items into an array. As this array contains everything, I enumerate and pick out those for which the project ID matches. As I do not need all properties from the original object, I elected to use a dictionary to store a subset for later processing.
Lastly, this array needs to be sorted by child_order to reflect the current sort in the application.
This is accomplished via def getTasksInProject(intPojectID, items).
Sorting project items
For the most part, the sorting code is vanilla bubble sorting. The difference is how we process the relevant properties:
Sorting by priority is a simple number comparison if tasks[i]['priority'] < tasks[i+1]['priority'] - only swapping on a difference of priority. Where items have the same priority, their order should remain unchanged. Displaced tasks retain their ordering.
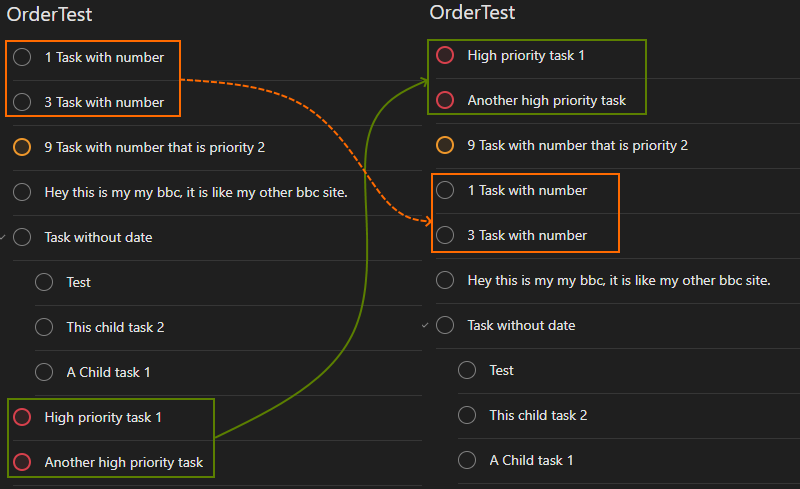
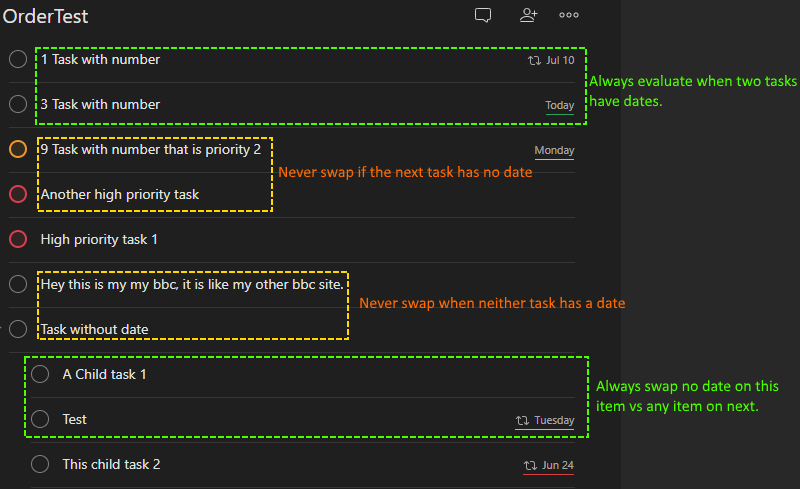
Sorting by due date required me to deal with the scenario the property might not be present as it is optional. Our permutations during the sorting passes were:
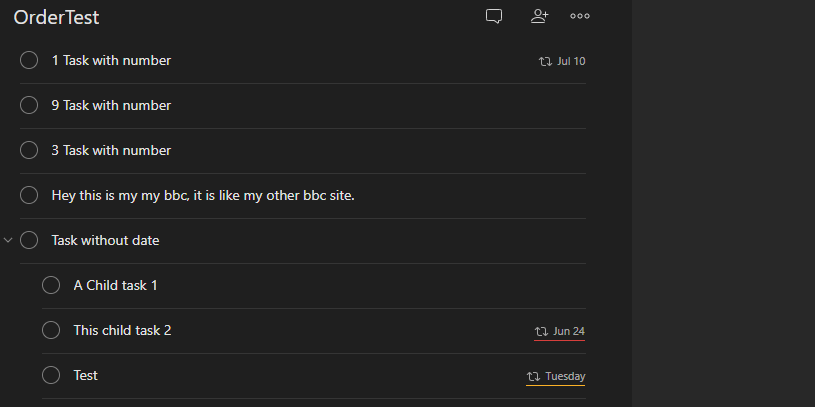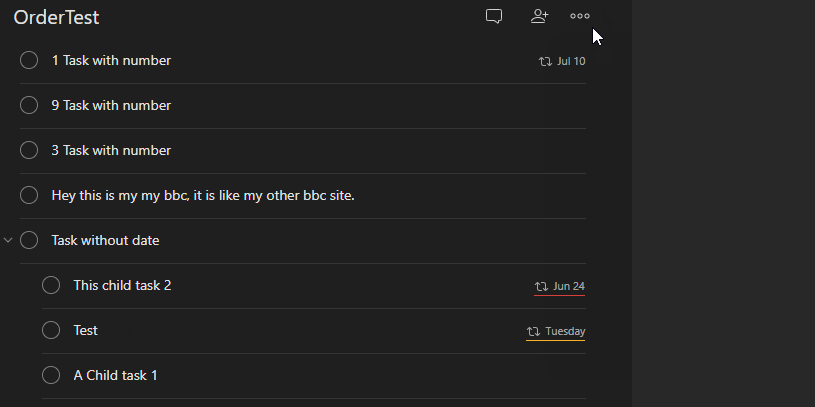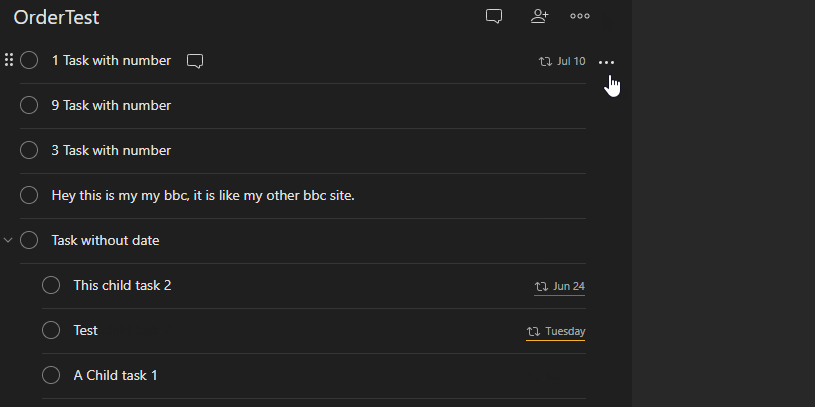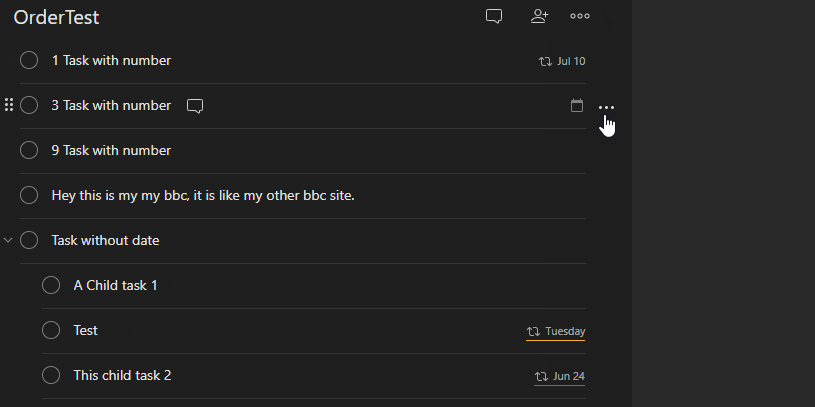
Sorting by name I underestimated. Initially, I processed the tasks with a similar approach to priority - using a lower() version of the content to ignore casing. However, an edge case emerged as I became aware that the value of content could contain markup.
The observed behaviour of the native Todoist application was that it considered only the visible text in sorting by name. In the following example, the content of this item starts with [ however, Todoist considers it m alphabetically:
Hey this is my [my bbc](http://www.bbc.co.uk), it is like [my other bbc](http://www.bbc.co.uk) site.
Would be treated as the following during sorting:
Hey this is my my bbc, it is like my other bbc site.
I experimented with several options eventually decided that a regular expression solution was a good fit. The visible text (a substring) is extracted and replaced the markup during the comparison.
strFindLinks = r"\[([^\]\[]*)\]\(([^\]\[]*)\)"`
strThisTaskContent = re.sub(strFindLinks, r"\1" ,strThisTaskContent)
You can see an example of this interactively on regex101.com which explains it well.
Deployment to Lambda
Once I had configured the library locally and tested successfully, I proceeded to create a Lambda layer from the Python virtual environment.
Upon executing the function for the first time I received the following error:
[Errno 30] Read-only file system: ‘/home/sbx_user1051’: OSError
It transpired that the cache location in the Todoist library (cache='~/.todoist-sync/'):) was not compatible with the Lambda environment.
I needed a location to hold the sync cache - however, the default directory was inaccessible. The Lambda security overview provided an answer:
Each Lambda execution environment also includes a writeable file system, available at /tmp. This storage is not accessible to other execution environments. As with the process state, files written to /tmp remain for the lifetime of the execution environment. This allows expensive transfer operations—such as downloading machine learning (ML) models—to be amortised across multiple invocations.
On this basis, I elected to modify the cache location to use /tmp. I also noted:
Though Lambda execution environments are never reused across functions, a single execution environment can be reused for invoking the same function, potentially existing for hours before it is destroyed. Functions can take advantage of this behaviour to improve efficiency by keeping local caches, reusing long-lived connections between invocations, and pre-computing common results.
This information shaped my decision on whether I would split the sorting code into several Lambda functions or not. A singular Lambda function would potentially have access to an existing sync cache.
Automation
I took an MVP approach and reused the state machine for my Label automation. I decided to form the input as follows:
{
"projects": [
{
"id": 149286779,
"sortby": "due"
},
{
"id": 221167130,
"sortby": "name"
},
{
"id": 151727741,
"sortby": "priority"
}
],
"ordered": "0"
}
I have two state machines run and scheduled independently via scheduled CloudWatch event rules.
While this allows me to prove the concept - there would be some value in merging them and migrating the Label sorting to the Sync API.
Conclusion
Going through this process has given me some appreciation as to why sorting operates as it does presently. A client-side sort and sync approach and an API to sort how you like is a measured approach to the problem.
Centralised automatic sorting at scale could be an expensive operation though it would be a fascinating problem to solve.
I’ll end this post by closing the Todist task I’ve been using to track this very post.

Acknowledgements
- The contributors to the test_api.py - my understanding of how to use the library came from these test cases.
Share this post