
Introducing async to my serverless text-to-speech player for jokes and quotes
Using AWS components, Cloudflare, and public APIs.

TL; DR
In this post, I revisit my serverless “jokes and quotes” player. The purpose was to remove the tight coupling between the client request and audio playback API source. To explore the issue, I have introduced DynamoDB to store pre-generated results.
Challenge overview
Logically, all the components of my existing solution depend on each other to succeed to deliver audio to the client. You can visualise it as follows:
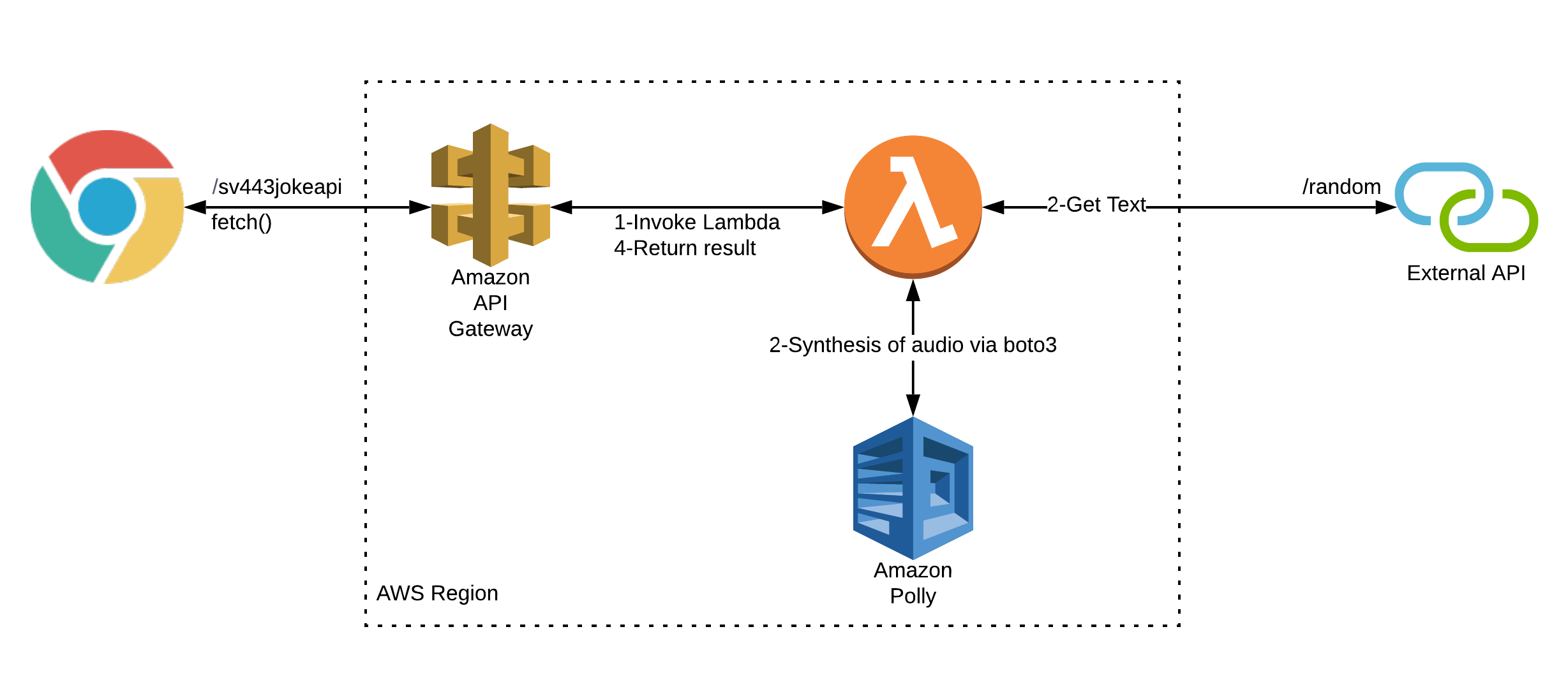
The challenge was to accomplish a solution which operated in the following fashion:
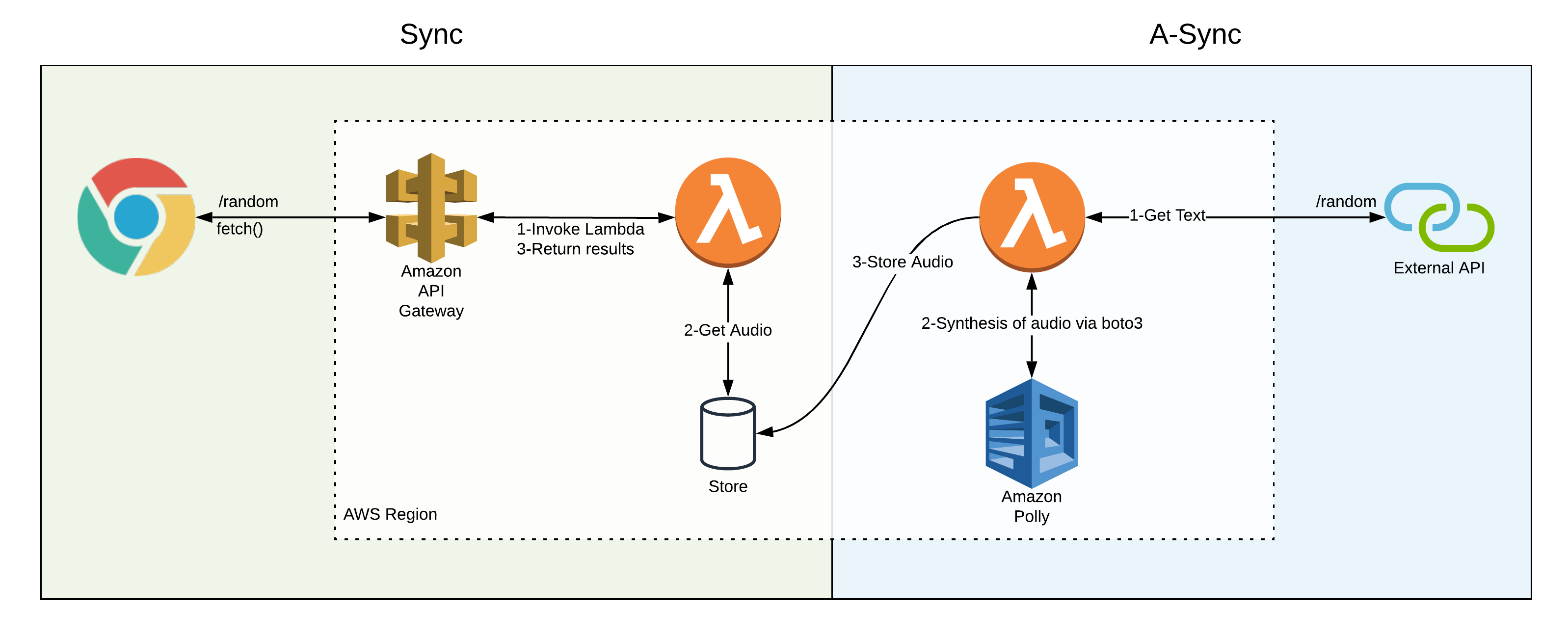
Separating the audio generation from the client call introduces some challenges.
- The external API generates a single random piece of text. My current code doesn’t contain the means to randomise results.
- The additional duties increase Lambda execution time. Not only will this increase the cost and complexity of the solution, but it could also be slower than the architecture it seeks to replace.
- The external API result doesn’t have any ID in the response that I could conveniently re-use. Therefore, I require a schema for whichever storage solution I use.
Solution detail
If there is one thing I’ve taken away from DynamoDB posts out there, its “know your access patterns” before starting. I decided on these patterns:
- Give me all entry IDs of a specific type.
- Play an entry with a specific ID.
As noted above, I had no re-usable ID, so I elected to convert the text into a SHA256 hash.
After some experimentation, I arrived with a record in the following format:
- Primary partition key: String. For example “QG” for Quote Garden.
- Primary sort key: String. For storing the hash of the source text.
- Attributes for
audio(the base64 encoded Polly result) andvoiceid(the AWS Polly voice name such as Joanna or Matthew).
Data access
The current implementation queries each partition, using a projection expression to return the hash IDs only. I use these to randomly construct the contents of the arrays in the JSON response to a GET query on /random:
{
"RS": [
"11d92af70459d90f3efbbd018a2abace0f4a37d5be6dd8d334168461799e598e",
"79d88ff378226da9e29b13a6a5b1abd816b082dacdea06694c51ab82e86e0978",
"e54ab1752bcf0a45f06b7e0dea786646569a085b5b544d48fad7e38ad928d122",
"b307378d79b25854cc4731483223111a3d3c20af70238a91f518ca6a7098f2d4"
],
"SV443": [
"095fa9ad0f7674a3f7f9255b488d2e16eb4a5127c73ce36126094a3d9407eaa1",
"24c613df2b1615906774c2d190f75fc4697a083aed48959ac48e02f52865c663",
"f2cefd0300eb4b13a05d72cb9deb4f839dd2aa5e6125f4286e42f419ec8e50f8",
"a11da89e11adf33299195e755929deef3cc02a6c6dd2098f50ddd561b74eeacf"
],
"ICH": [
"fb6ca232486dd950f03dbb56df88f0a3e554e4e211432013ca1936ad5b1478a1",
"b1e4032317afb0c2a546f1eb70f99cad50b2549eddbb18196167ffdd51893289",
"4cca36b2cec8fc9ab5083c10f31bfcaaea8aa907de1fa60ec10e8d4a4035746f",
"6f8936c043efee8325aeef8c6936b1b08162e7a3980522cba8d3c129d80dfe44"
],
"QG": [
"c2be41f3836130619815fa72de46d98bd98565197c91e727a9bd59cdaf3deb6b",
"25bc70bec45b3ae74fcadcccd8948d0c406a5812fa2147c05b57e88d27141d8c",
"e9adde34f55aa8dff01926c91fe31feeaeeba82039c4376bf9fbc431fdb47440",
"3d482ac017e61390dd6c9ee49651b7c516a1236a3c92802cc00f6108fb1fab8c"
],
"lastSeen": "2020-04-24T13:44:04"
}
Getting a specific entry
I’ve created an API route for each partition which expects the SHA256 ID as a query string parameter in the URL. For example:
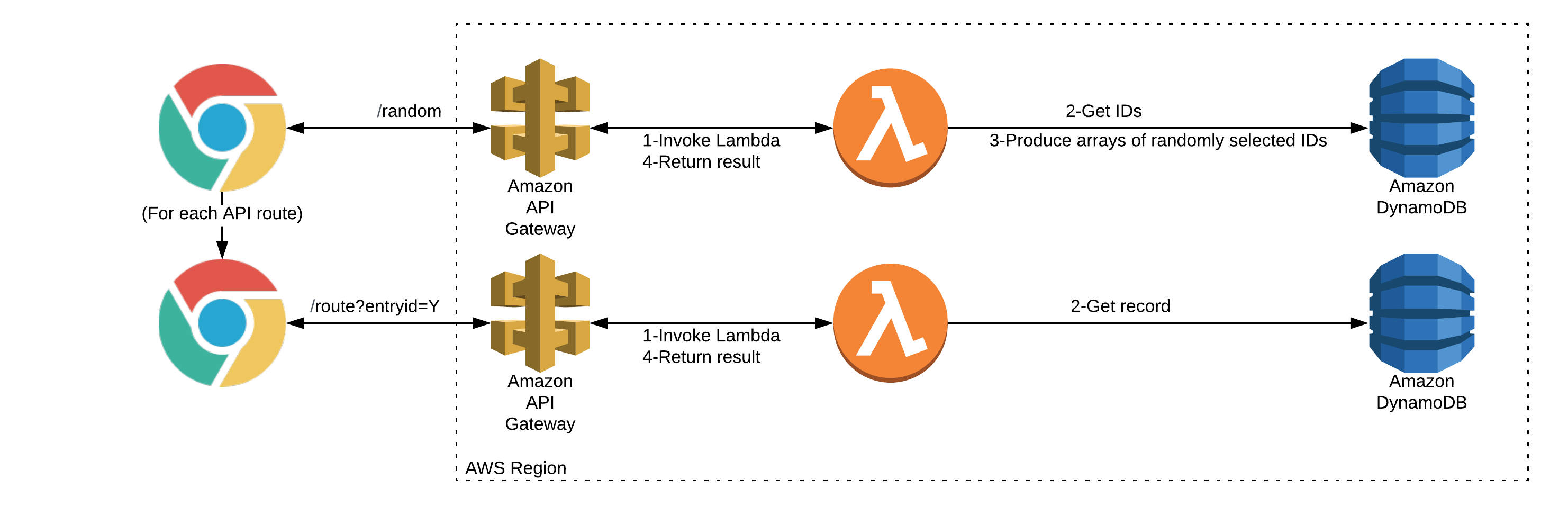
In case the entry is not present, I return a “404” style response with an audio clip reserved for that scenario.
Speed and cost of execution
The /random API route is expensive from an I/O perspective. Here is what happens if a few queries happen in quick succession:
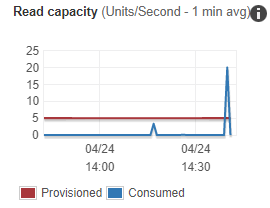
I’ve elected to cover this route and others with Cloudflare caching. Generally speaking, each API call duration is about 500ms when working with a warm Lambda, with caching it is usually less than 50ms. Additionally, each cache hit means one less execution for my AWS resources to perform.
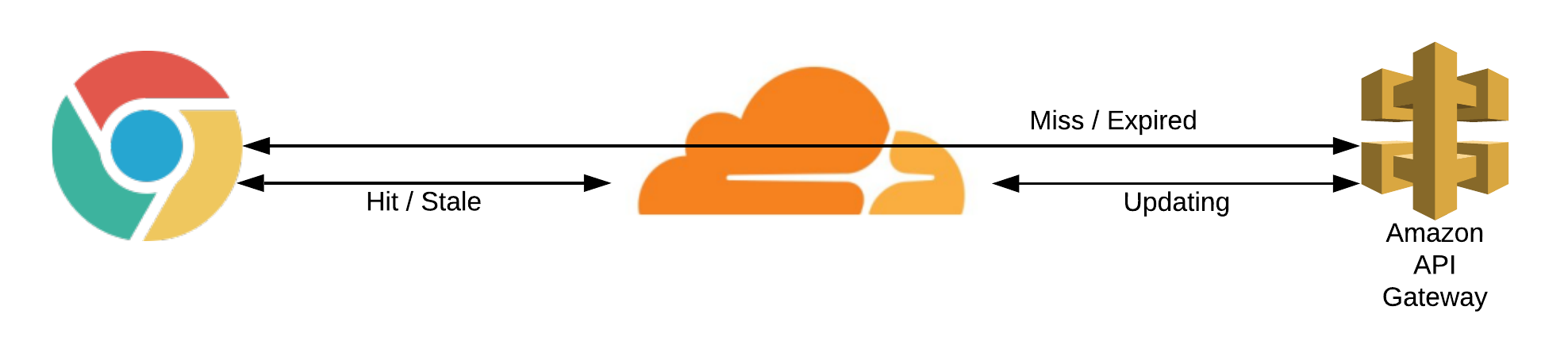
We can observe the Cloudflare cache status via a header in the response (“cf-cache-status”) and its effects on response time below:

Note the effects of all entry routes with a cache hit:

And the effects of the /random route cached as well:

Whenever we achieve 100% caching within Cloudflare, the response time is much improved.
The /random route caches for the plan minimum (2 hours) whereas I can cache the specific entries for much longer.
Conclusion
I’ve learned a lot researching and experimenting for this. There is scope for plenty of future experiments with this subject matter.
Acknowledgements
- James Wright for Ron Swanson API.
- Alex DeBrie for dynamodbguide.com, a great learning resource.
- OpenMoji for the ballon, book and speech parrot. I have modified the colours on the parrot.
- The Lorem Ipsum site for their generator.
Share this post