
Backup of Cloudflare DNS to AWS DynamoDB
Using AWS Lambda to copy records into DynamoDB via the Libcloud library

TL; DR
After a short break, I decided to take an item off the project list. DNS is a rich source of inspiration for me - and so I elected for a quick win in the form of serverless DNS records backup. The goal of which is to backup my DNS zone contents, via functions as a service (FaaS) and storage as a service (object or database).
You can find all the associated code for this on my GitHub page.
Getting started
My DNS zone, at the time of writing, is hosted with Cloudflare. They provide an API with the capability to list records.
Addressing the speed aspect of a quick win, I decided to access these records via a library rather than using the API directly. I have previously used Apache’s Libcloud Python library for other projects and found Cloudflare support within.
Getting a list of records was only a few lines of code away:
- Import library
- Instantiate the provider driver for Cloudflare
- Obtain the zone ID (at one-time action when working with single domain setups such as mine)
- Call the list_records() method and process the results.
Retrieving your zone ID
driver = cls(cfUsername, apiKey)
zones = driver.list_zones()
print(f'{len(zones)} zone(s) found')
for zone in zones:
print(zone.id,zone.domain)

Working with the record data in Libcloud
The record object is composed of some common attributes across record types, and an attribute called extra. Extra is a dictionary of values specific to the driver or record type. Proxied would be specific to Cloudflare, whereas priority would be specific to record types such as MX and SRV. Below is an example of the available data:
vars(thisRecord)
{'id': 'cf_generated_id',
'name': 'ja',
'type': 'A',
'data': '151.101.1.195',
'zone': <Zone: domain=mesmontgomery.co.uk, ttl=None, provider=CloudFlare DNS ...>,
'driver': <libcloud.dns.drivers.cloudflare.CloudFlareDNSDriver object at 0x10078a810>,
'ttl': 300,
'extra': {'data': None, 'locked': False, 'proxiable': True, 'modified_on': '2019-03-09T15:27:48.310054Z', 'proxied': False, 'created_on': '2019-03-09T15:27:48.310054Z'}}
Working with DynamoDB and Lambda
My only prior experience with DynamoDB is my Elite Dangerous timeline project, and I operated that instance locally. On this occasion, I would be storing the information of interest into a table hosted on the live DynamoDB service.
What are my intended goals?
- Document DNS records as last seen when crawling the API; and
- Maintain a history of modifications and deletions. But not indefinitely.
To that end, I created a DynamoDB table as follows:
- The primary key set as the Cloudflare record ID
- With a secondary sort key as the Cloudflare modified_on record value
The Lambda function processes each record and also stores the following:
- Record values of interest (name, data/content, type, TTL, priority)
- Last seen epoch (by my Lambda script) value of now.
- An expires epoch value set one week into the future.
To use the Libcloud library within Lambda, I created a layer and attached it to my function.
Below is an example of the function running:
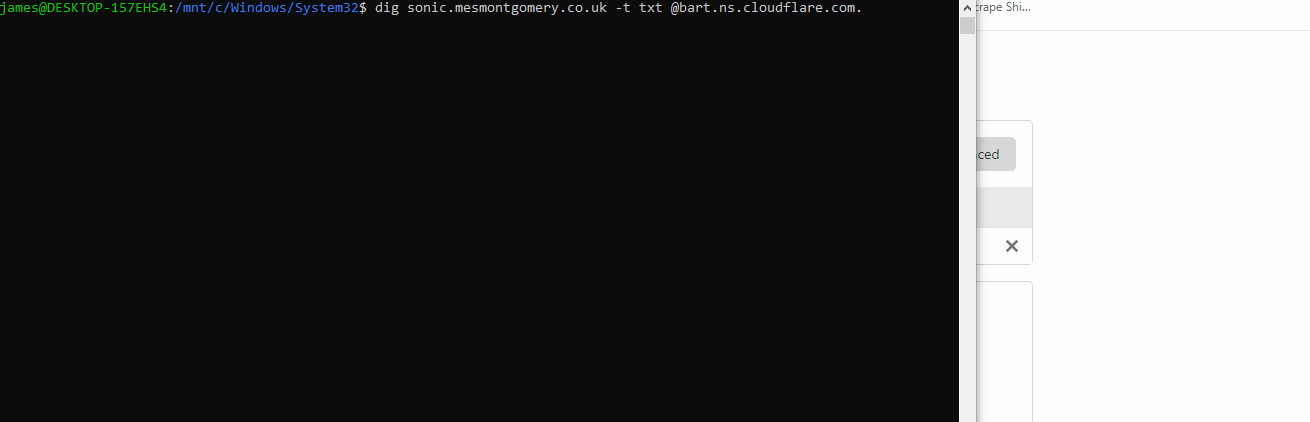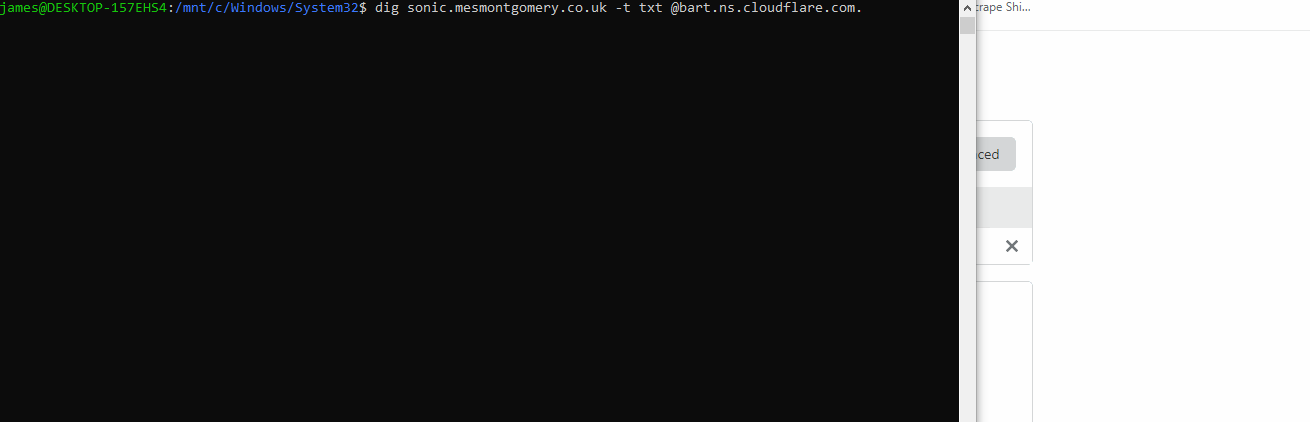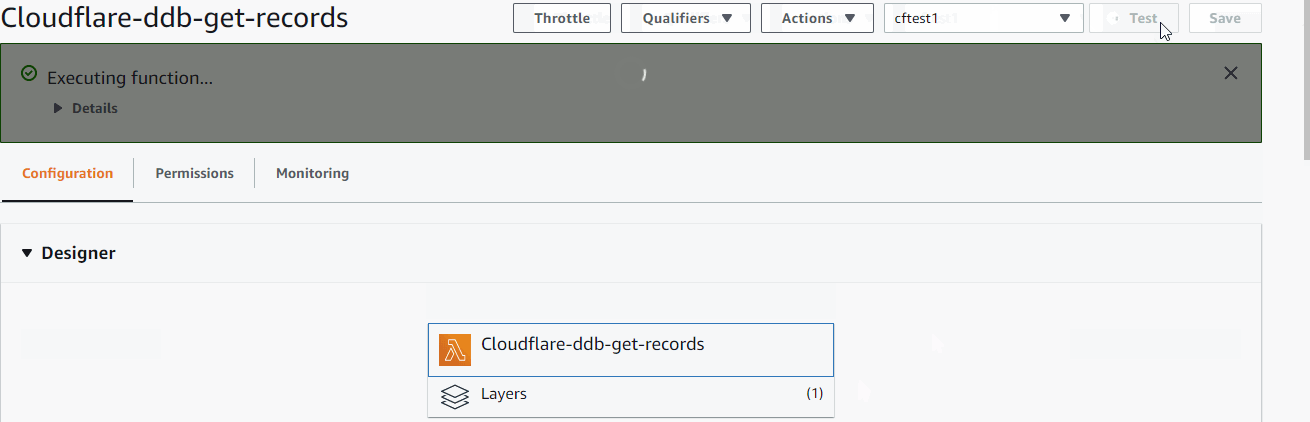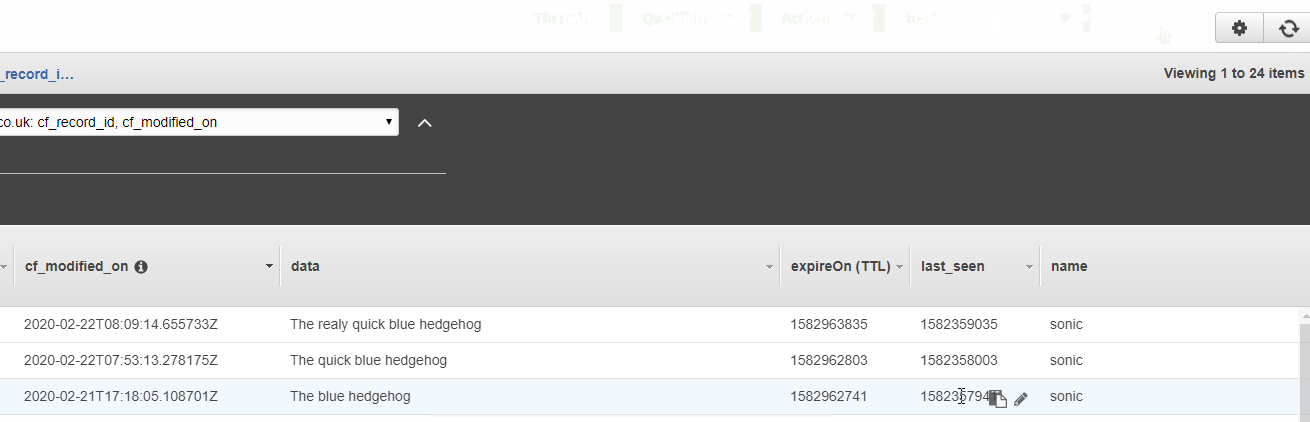
You’ll observe me:
- Performing an authoritative lookup of
sonic.mesmontgomery.co.ukagainst a Cloudflare name server. - Editing this record in the Cloudflare UI, because Sonic is really quick. The sharper eyed amongst you may spot the spelling mistake; it was a one-take capture. And I missed the Grammarly prompt too 🤦♂️.
- I show the three top results in the database. There are twenty-three, to begin with, and two of those are different versions of the sonic record already.
- My Lambda function is executed and now there are twenty-four records.
- I refresh the DynamoDB query (which you’ll note is sorted by ‘cf_modified_on’). The top three records are all Sonic related.
TTL
In the recording above, you may notice an ’expireOn (TTL)’ field. When I began this project, I expected to have to lifecycle my records with Lambda functions. As I collected deleted records or record history, they would remain forever without deleting them.
I was surprised and delighted to see that this functionality is native to DynamoDB - without cost.
Processing takes place automatically, in the background, and doesn’t affect read or write traffic to the table. Also, deletes performed via TTL do not count towards capacity units or request units. TTL deletes are available at no additional cost.
Backup
I’ve elected to enable point-in-time recovery on the table to experiment with the feature. As my table is KB in size, even if the storage charges aren’t free-tier applicable, it won’t be a noticeable cost.
PITR is a continuous backup function for the last 35 days. As I maintain a record history and deletions in the database, I can go as far back as I configure in the function at the cost of additional storage in the table.
The case of missing priority
When I first used Libcloud, I tried using the export zone to file method. I wasn’t successful in using it; however, I noted the error message (KeyError: ‘priority’) and vowed to return to it.
As I was completing my record attribute review, priority was one of the last to add. And it wasn’t present in the returned data.
I checked the official API documentation to determine if this was a supported result. In the end, I reviewed the Libcloud driver itself and found what I believed to be an omission in the Extra dictionary.
To work around the issue, I modified the driver file (drivers/cloudflare.py) to include priority in RECORD_EXTRA_ATTRIBUTES and opened an issue on GitHub.
That fix was confirmed and merged into the trunk version. 😃
Conclusion
I’m happy to take off a long-standing item on my to-do list. It was fun to explore a serverless solution to the problem. Should I wish to automate this, a Cloudwatch scheduled event would do the job.
Share this post